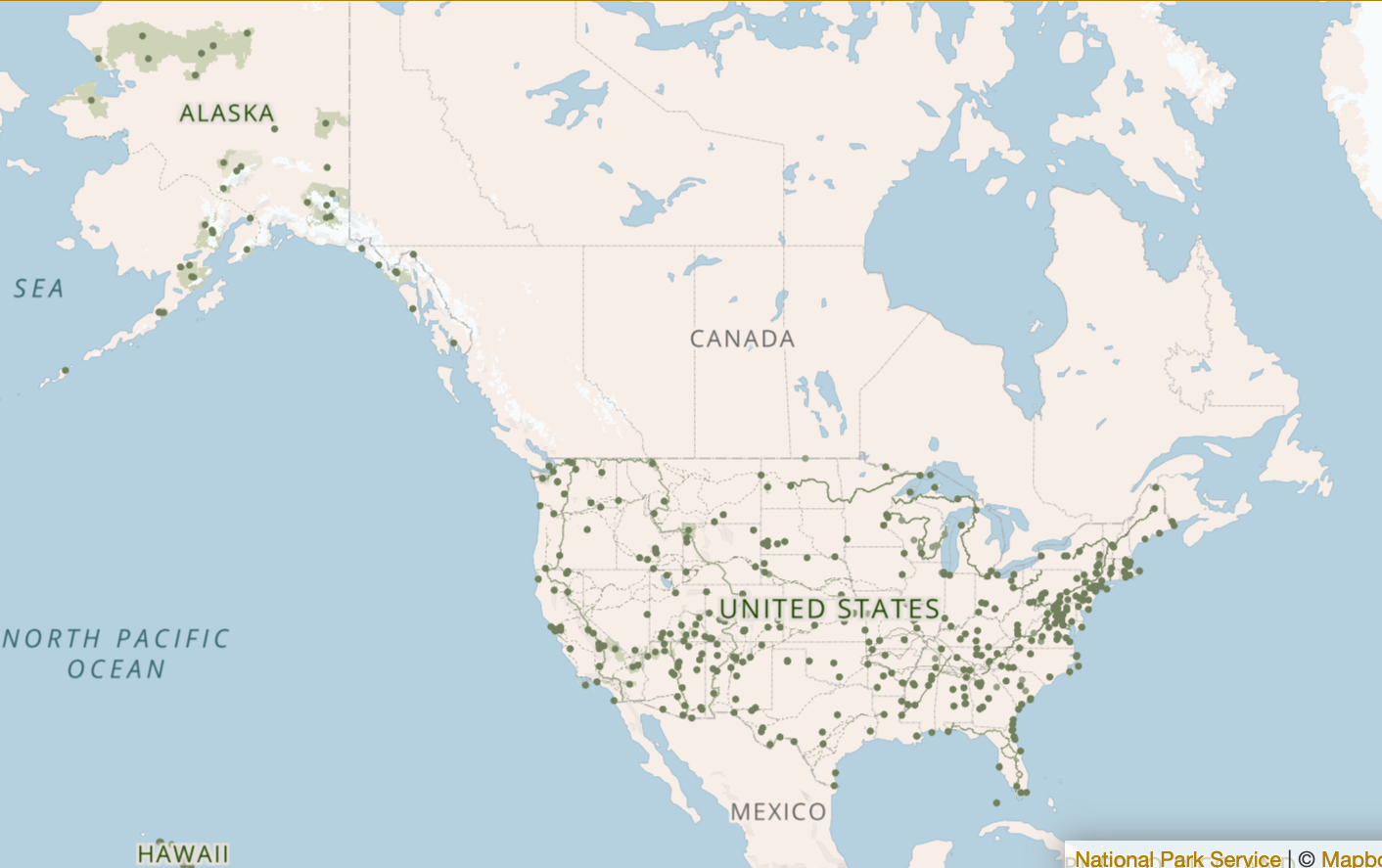
US National Parks sample data now available!
My dear wife and I like to travel and explore nature. Naturally, US national parks are always high on our […]
My dear wife and I like to travel and explore nature. Naturally, US national parks are always high on our […]
It’s actually been quite a while since I put together these free sample data sets for everyone but it just
Hi everyone! This blog hasn’t seen any updates since over a year now and I do apologize for that. However,
The WordPress.com stats helper monkeys prepared a 2012 annual report for this blog. Here’s an excerpt: 4,329 films were submitted
Today I was part of a NYOUG seminar about “Indexing Strategies” held by Mr. Jonathan Lewis himself. If somebody doesn’t
The stats helper monkeys at WordPress.com mulled over how this blog did in 2010, and here’s a high level summary
I spent the last couple of days with coding a new registration module for a private website that I administrate.
A couple of weeks ago a customer had some troubles with the overall performance. He complained that everything is slow
TIOBE just released the “Tiobe programming community index” for April 2010. And guess what – C is back on top
Then you get registration emails like this: Hello $users.firstname! Your username is: $users.Login
Here is a good short article from a guy called Jackson about coding practices. Take a few moments to read